Parser 동작 방식
Parsing이란?
문서 파싱은 브라우저가 코드를 이해하고 사용할 수 있는 구조로 변환하는 과정이다. 주어진 문서를 가지고 브라우저가 바로 해당 문서를 조작할 수 없고, 이러한 문서에 대해 어휘분석과 구문 분석 과정을 거쳐 파싱 트리를 구축한다. 이 과정에서 오류가 있는 노드들은 파싱 트리에 추가되지 않고, 일치하는 노드만 추가시킨다.
xml Parsing
xml Parsing - DOM
DOM은 XML 문서를 나타내는 객체들의 인터페이스를 표준으로 정해놓은 것으로, DOM 파서는 바로 XML 문서로부터 DOM 구조를 생성한다.
그렇게 만들어진 대표적인 DOM 구조가 HTML이다.
 이렇게 만들어진 DOM은 트리 형태로 아래로 내려가면서 뻗어나가는 구조를 가진다.
해당 구조는 객체 안에 다른 객체들이 들어가 있는 방식으로 설계되어 있다.
브라우저의 DOM에 변경이 일어나면 변경된 DOM과 기존 DOM을 비교한 뒤, 변경이 일어난 부분을 업데이트 시키는 과정을 ‘리렌더링’이라고 한다.
이렇게 만들어진 DOM은 트리 형태로 아래로 내려가면서 뻗어나가는 구조를 가진다.
해당 구조는 객체 안에 다른 객체들이 들어가 있는 방식으로 설계되어 있다.
브라우저의 DOM에 변경이 일어나면 변경된 DOM과 기존 DOM을 비교한 뒤, 변경이 일어난 부분을 업데이트 시키는 과정을 ‘리렌더링’이라고 한다.
장점
- XML 문서에 대한 구조적 접근에 용이하다
- 문서의 일부분에 대한 업데이트가 자주 필요할 때 용이하다
단점
- 메모리 사용이 많음
- 속도가 느림
xml Parsing - SAX
SAX는 문자열을 앞에서부터 차례로 읽어가면서 요소, 속성이 인식될 때마다 Event를 발생시킨다. 각각의 Event에 대하여 핸들러를 구현하는 프로그래밍이다. 앞에서부터 차례로 하나의 긴 문자열을 읽어 가는 것처럼 읽어가면서 이벤트 핸들러(콜백함수)를 작동시켜 구조화시키는 방식이다.
장점
- 문서의 일부분 데이터 변환이나 유효성 처리에 유효하게 쓰인다.
- 순차 처리에 유용하다
- XML 문서 구조가 간단하다
- 메모리가 적게 들고 속도가 빠르다
단점
- 문서 일부분에 대한 임의의 접근 불가능
- 이벤트나 작업 상태를 직접 보관해야 한다.
- 문백 정보의 유지가 없다
- 내용 수정이 불가능하다
DOM과 SAX의 차이점
DOM은 전체 문서를 메모리상에 올려놓고 처리하기 떄문에 수정과 추가가 용이하지만, SAX의 경우에는 처음부터 끝까지 순차적으로 문자열을 돌면서 처리하기 때문에 문자열 하나하나만이 메모리에 올라가 메모리 사용이 적지만 특정 요소를 찾아 수정하는 기능은 불가능하다.
XML이란?
Extensible Markup Language(XML)의 약자이다. 공유 가능한 방식으로 데이터를 정의하고 저장할 수 있는 확장성 높은 마크업 언어이다. 웹 사이트, 데이터베이스 및 타사 애플리케이션과 같은 컴퓨터 시스템 간의 정보 교환을 지원한다. 사전 정의된 규칙을 사용하면 수신자가 이러한 규칙을 사용하여 데이터를 효율적으로 정확하게 읽을 수 있으므로 모든 네트워크에서 데이터를 XML 파일로 손쉽게 전송할 수 있다.
데이터 태그에 대하여 속성, 값들을 보다 효율적으로 처리할 수 있어 많이 사용된다.
주요 장점으로는
- 비즈니스 간 트랜잭션 지원
- 데이터 무결성 유지
- 데이터 손실 방지
- 일관된 데이터 저장
- 검색효율성 향상
- 검색 크롤러가 XML 문서에 대해 정확하게 분류가 가능해 검색에 뜰 확률이 높다.
- 리액트가 검색효율성이 낮은 이유도 일반적인 DOM이 아닌 Virtual DOM을 사용해서 이기도 하다
- 유연한 애플리케이션 설계
- XML은 이미 많이 사용되기 때문에 XML 데이터 지원 툴이 많아 처리가 용이하다.
등이 있다.
XML과 HTML의 차이점
HTML(HyperText Markup Language)은 대부분의 웹 페이지에서 사용되는 언어이다. 웹 브라우저는 HTML 문서를 처리하여 멀티미디어 페이지로 표시합니다. W3C는 웹 사이트 개발자가 일관성과 품질을 위해 구현하는 HTML 및 확장 가능한 마크업 언어(XML) 표준을 모두 확립했다.
- 용도
- HTML의 용도는 데이터를 표시하는 데 사용되지만 XML은 데이터를 저장하고 전송할 수 있다.
- 태그
- HTML에는 미리 정의된 태그가 있지만 사용자는 XML에서 고유한 태그를 만들고 정의할 수 있다.
- 구문 규칙
- XML은 대/소문자를 구분하지만 HTML은 구분하지 않는다.
<book>대신<Book>으로 태그를 작성하면 XML 구문 분석기에서 오류가 발생한다.
JSON 데이터 표현과 방식
JSON이란
JavaScript Object Notation (JSON)은 Javascript 객체 문법으로 구조화된 데이터를 표현하기 위한 문자 기반의 표준 포맷이다. Javascript 객체 문법과 매우 유사하지만 딱히 Javascript가 아니더라도 JSON을 읽고 쓸 수있는 기능이 다수의 프로그래밍 환경에서 제공되어 API로 데이터를 전송할 때 일반적으로 사용한다. JSON은 문자열 형태로 이루어져 있다. 이러한 특성은 네트워크를 통해 전송할 때 유용하다.
{
"squadName": "Super hero squad",
"homeTown": "Metro City",
"formed": 2016,
"secretBase": "Super tower",
"active": true,
"members": [
{
"name": "Molecule Man",
"age": 29,
"secretIdentity": "Dan Jukes",
"powers": ["Radiation resistance", "Turning tiny", "Radiation blast"]
},
{
"name": "Madame Uppercut",
"age": 39,
"secretIdentity": "Jane Wilson",
"powers": [
"Million tonne punch",
"Damage resistance",
"Superhuman reflexes"
]
},
{
"name": "Eternal Flame",
"age": 1000000,
"secretIdentity": "Unknown",
"powers": [
"Immortality",
"Heat Immunity",
"Inferno",
"Teleportation",
"Interdimensional travel"
]
}
]
}js와 다른 점이라고 한다면 객체의 key값에 따옴표 ""를 붙인다는 것 말고는 크게 다른 점이 없다.
js에서는 JSON.stringify()라는 메서드가 존재하며, js의 값이나 객체를 JSON 문자열로 손쉽게 변환할 수 있다.
JSON.stringify(value[, replacer[, space]])- value
- JSON 문자열로 변환할 값.
- replacer
- 문자열화 동작 방식을 변경하는 함수, 혹은 JSON 문자열에 포함될 값 객체의 속성들을 선택하기 위한 화이트리스트(whitelist)로 쓰이는 String 과 Number 객체들의 배열. 이 값이 null 이거나 제공되지 않으면, 객체의 모든 속성들이 JSON 문자열 결과에 포함된다.
- space
- 가독성을 목적으로 JSON 문자열 출력에 공백을 지정
XML과 JSON 데이터 구조와 값 표현에서 공통점과 차이점
XML도 데이터 교환에 많이 쓰였던 데이터 구조이다. JSON도 데이터 교환에 사용되지만, JSON은 XML보다 새롭고 유연하며 널리 사용되는 옵션이다.
공통점
- 데이터 직렬화 방식이다.
- 표준화된 방식으로 데이터 교환이 가능하다
- 통일된 데이터를 가지고 다르게 표현이 가능하여 모든 언어에서 만들기 용이하다.
- 트리구조로 되어 있다.
- 다른 API 표현하는 데이터 방식보다 읽기 편하다.
- 플래폼 상관없이 사용 가능
차이점
- XML은 트리 패턴으로 데이터를 나타내지만, JSON은 객체와 비슷한 키-값 페어를 사용해서 트리 구조를 나타낸다.
- JSON이 객체를 쉽게 정의할 수 있어 사용성이 좋다.
- XML 구문 분석기로 인해 느려지는 판면,, JSON의 경우 보다 빠르게 구문 분석이 가능하다.
- JSON은 문자열, 숫자, 객체 등의 boolean값을 지원할 수 있다.
- XML에서는 boolean값을 지원하지 않는다.
- XML은 태그 구조로 이루어져 있어 보다 복잡한 경향이 있다.
- XML 방식보다 JSON이 보안에 좋다.
- XML 구조는 외부 엔터키 삽입이나 무단 수정에 취약하다.
- 유연하다.
- JSON은 주석이 없지만 ,XML은 !로 주석을 붙일 수 있음
- 태그 중첩이 복잡하게 얽혀있음
- 태그로 정해져있는 부분이라 가독성이 떨어짐
- JSON은 탭으로 구분이라 보다 가독성이 좋음
컴파일러 이론
컴파일러란?
고급 언어의 프로그램을 어떤 특정한 컴퓨터에서 직접 실행 가능한 형태의 프로그램으로 번역 고급어 → 기계어
컴파일러의 내부 과정
 어휘 분석 → 구문 분석 → 중간 코드 생성 → 코드 최적화 → 목적코드 생성의 단계를 거친다.
어휘 분석 → 구문 분석 → 중간 코드 생성 → 코드 최적화 → 목적코드 생성의 단계를 거친다.
function compiler (originCode) {
var ast = syntaxAnalyzer (tokens)
var targetcode = codeGenerator (ast)
return targetCode
}이와 같이 의사코드로 작성할 수 있다.
Lexical Analyze
Tokenizer
어떤 구문을 토큰화 하는 역할을 한다. 토큰은 어휘 분석의 단위를 뜻하며, 단어/단어구/문자열 등 의미있는 단어로 정해진다.
프로그래밍 언어에서 사용하는 토큰의 종류
- identifier : 식별하기 위한 이름
- keyword : 미리 지정한 예약어
- separator : 글자를 구분하는 문자
- operator : 연산을 위한 심볼
- literal : 숫자, 논리, 문자
- comment : 줄 또는 블록 코멘터리
| 토큰이름 | 샘플 |
|---|---|
| identifier | HTML, BODY |
| separator | <, >, [, ], , |
| operator | +, <, = |
| literal | true, NULL, 3.14, “hello” |
| comment | <!코멘트는 무시> |
Lexer
 Tokenizer로 인해 쪼개진 토큰들의 의미를 분석하는 역할을 한다.
Tokenizer → Lexer 의 단계를 거쳐 의미를 분석하는 과정을 Lexical Analyze라고 한다.
Tokenizer로 인해 쪼개진 토큰들의 의미를 분석하는 역할을 한다.
Tokenizer → Lexer 의 단계를 거쳐 의미를 분석하는 과정을 Lexical Analyze라고 한다.
Parser
 Lexical Analyze된 데이터를 구조와하는 기능ㅎ이다.
여기서 데이터가 올바른지 검증하는 역할인 구문 분석(Syntax Analyze) 또한 이루어질 수 있다.
Parser에 의해 도출된 결과는 AST(Abstract Syntax Tree) 형태로 생성된다.
Lexical Analyze된 데이터를 구조와하는 기능ㅎ이다.
여기서 데이터가 올바른지 검증하는 역할인 구문 분석(Syntax Analyze) 또한 이루어질 수 있다.
Parser에 의해 도출된 결과는 AST(Abstract Syntax Tree) 형태로 생성된다.
AST(Abstract Syntax tree)
 분석된 구문을 트리의 형태로 나타내는 자료구조이다.
이렇게 만들어진 트리는 다시 code generator로 들어가 실행하게 된다.
분석된 구문을 트리의 형태로 나타내는 자료구조이다.
이렇게 만들어진 트리는 다시 code generator로 들어가 실행하게 된다.
정규표현식
- 컴파일러의 Lexer에서 토큰을 찾아내는데 있어서 기준이 되는 표현식
- 정규 언어를 기술하는 수학적 표현
- 정규 표현식 E라면 L(E)는 E를 정의하는 언어
정규표현식과 오토마타
- 정규표현식과 오토마타는 Equivalent함.
- 모든 정규표현식에 대해서 동일한 언어를 만족하는 오토마톤 구성 가능
- 오토마톤이 주어지면 동일한 언어를 만족하는 정규표현식 구성 가능
- 정규표현식과 오토마톤의 상호 변환
- RE(정규표현식) → e-NFA → NFA → DFA 순서로 생성 가능
- DFA(오토마톤) → NFA → e-NFA → 정규표현식 순서로 생성 가능
정규표현식 패턴
- 불리언 or
- | : gray | grey
- 그룹
- () 소괄호 : gr(a|e)y
- 반복횟수
- ?(0 또는 1번) : colou?r
- ** (0 또는 반복) : gogle
-
- (1번 이상 반복) : go+gle
- {n} : 정확히 n번
- {min, max} : 최소 min 만큼, 최대 max만큼
- . (모든 문자와 일치) : a.
- [[] (문자 집합 요소 중에 하나와 일치) : [a-z]
- \[^] (문자 집합 요소 제외하고 일치) : [^b]at
- \\ (바로 다음 문자 이스케이프): a\.
오토마타 이론
- 상태(State)들의 유한한 집합(Set)
- 주어진 규칙(Rule)에 따라 특정 상태에서 다른 상태로 전이(transition)
유한(Finite) 오토마타 표현
- 상태는 노드로 표시
- 상태 전이는 방향 있는 화살표(directed edge)
- 전이 규칙은 화살표 옆에 레이블(Label)

문자열 중에서 특정 단어를 인식하기
- 해당 과정을 오토마타 표현을 했을 때
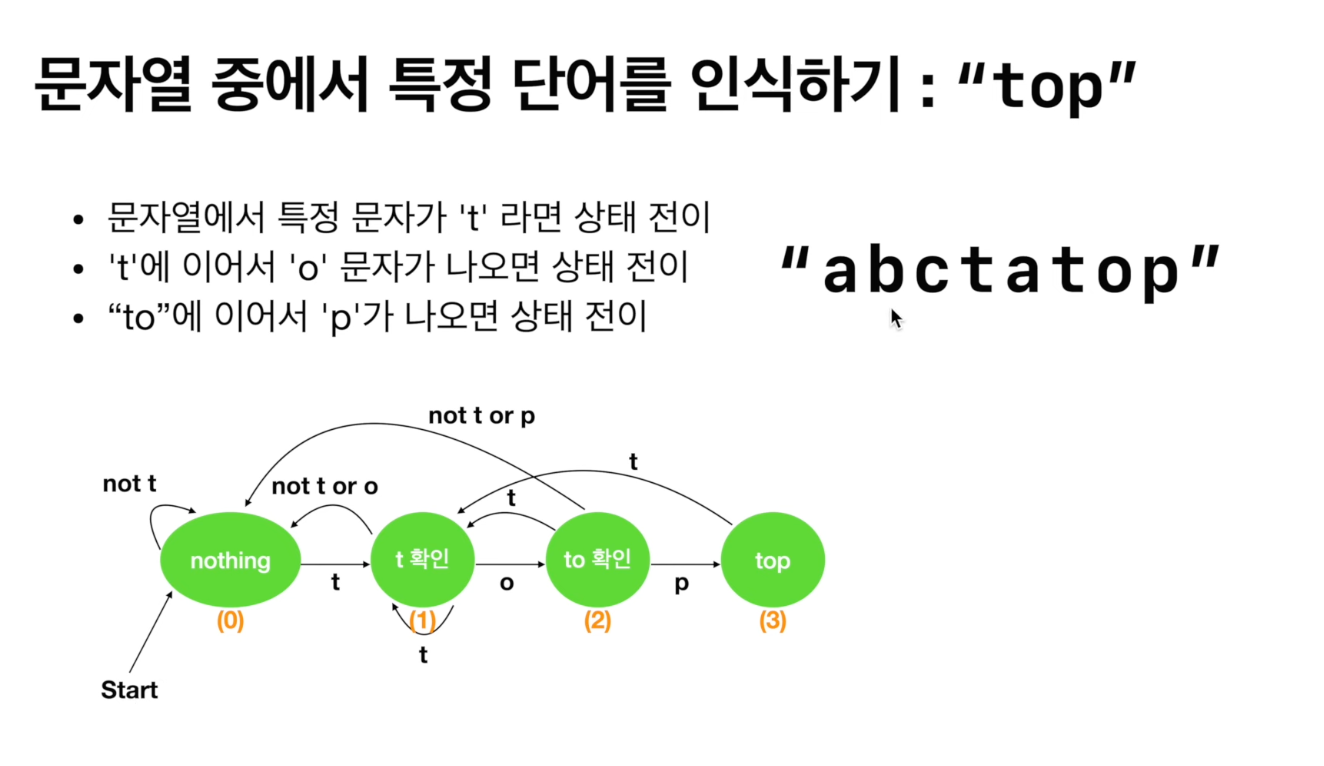
- 각 문자를 확인하면서 나오는 상태에 대해서 표현
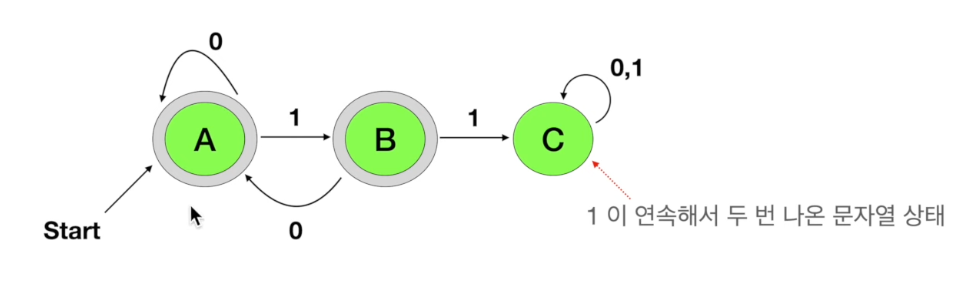
DFA(Deterministic Finite Automata)
- 결정적이기 때문에 다음 상태로 넘어갈 수 있는 것들이 명확한 것들을 의미
DFA 그래프 표현
- 상태들 → 노드(Nodes)
- 상태 전이 함수 → 화살표(Arcs)
- 시작 상태는 start로 표기한 화살표가 가리키는 상태
- 최종 사상태는 이중 동그라미로 표시
DFA 전이표(Transition Table)
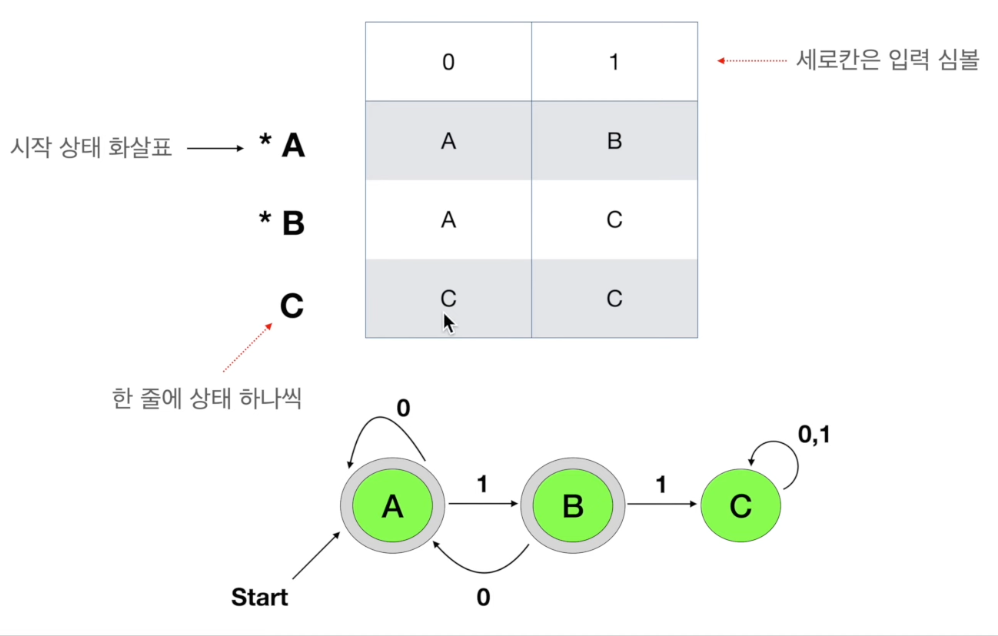
- DFA를 표로 만들어 어떤 입력이 들어오느냐에 따라서 시작 → 도착 상태를 표로 만든 것
- 배열로 만들어 구현
확장 상태 전이 함수
- 재귀 함수로 구현
- 입력이 문자열인 경우 상태 전이 함수
- 문자열을 구성하는 문자를 한 개씩 처리해서 최종 상태에 도달

- 문자열을 구성하는 문자를 한 개씩 처리해서 최종 상태에 도달
DFA 언어(Language)
- 모든 종류의 오토마타는 ‘언어를 정의한다’
- A라는 오토마톤(automatone)이면 L(A)는 A의 언어를 의미
- L(A)는 DFA A로 인식가능한 언어
- 시작 상태부터 최종 상태까지 경로 라벨링(labeling) 문자열 집합
- 해당 문자열을 상태에 따라 다 처리하고 나면 최종 상태에 도달
정규 언어(Regular Languages)
- DFA 중에서도 특정한 언어로, DFA가 존재하고 DFA(L)을 만족하는 문자열
- 해당 DFA는 오직 L에 있는 문자열만 만족함
- 대우에 의한 증명 + 귀납적 증명이 된 언어
NFA(non-deterministic Finite Automata)
- 하나의 입력 문자에서 여러 상태로 이동 가능한 오토마타
- 여러 상태로 이동 가능해서 비결정적(non-determinism)이라고 함
- 예) 01로 끝나는 문자열을 만족하는 NFA
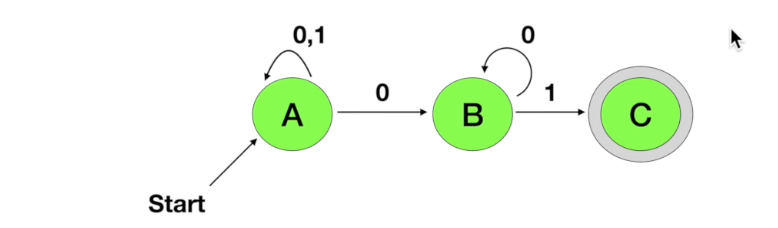
- 먼저 0을 입력하여 상태 B로 갔다가 B에서 맞는 상태가 아니면 백트래킹이 생겨 돌아가는 형태
- 예) web과 ebay를 인식하는 단어
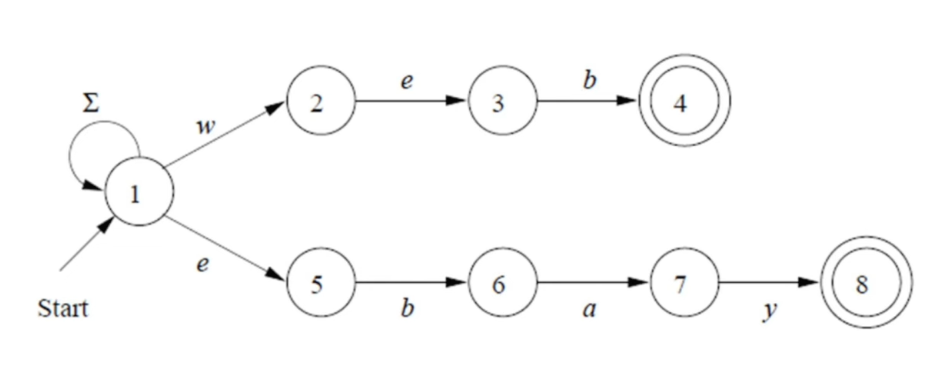
- 해당 상태에서 web의 단어에서는 ‘webay’일 경우 web이 아닌 ‘ebay’로 인식해야 하기 때문에 백크래킹을 해야 할 필요성이 생긴다.
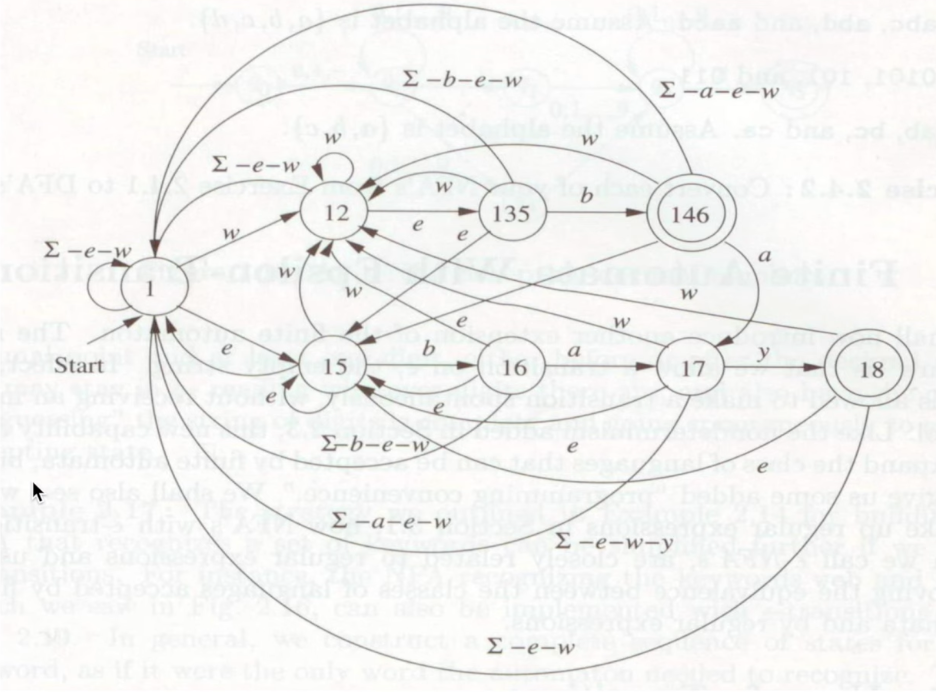
- 이러한 상태의 전이를 표현하기에는 배우 복잡해지는 형태가 됨
- 따라서 NFA는 프로그램으로 직접 대응해서 구현이 불가능하다는 특징이 있음
- DFA만 프로그램으로 구현이 가능하다
- 해당 상태에서 web의 단어에서는 ‘webay’일 경우 web이 아닌 ‘ebay’로 인식해야 하기 때문에 백크래킹을 해야 할 필요성이 생긴다.
- NFA는 DFA와 동등(equivalent)하다.
- 인식하는 언어의 범위가 동일
- NFA는 DFA로 변환 가능하다.
- NFA로 디자인하면 상태 전이 설계가 단순해진다.
한글 조합 오토마타
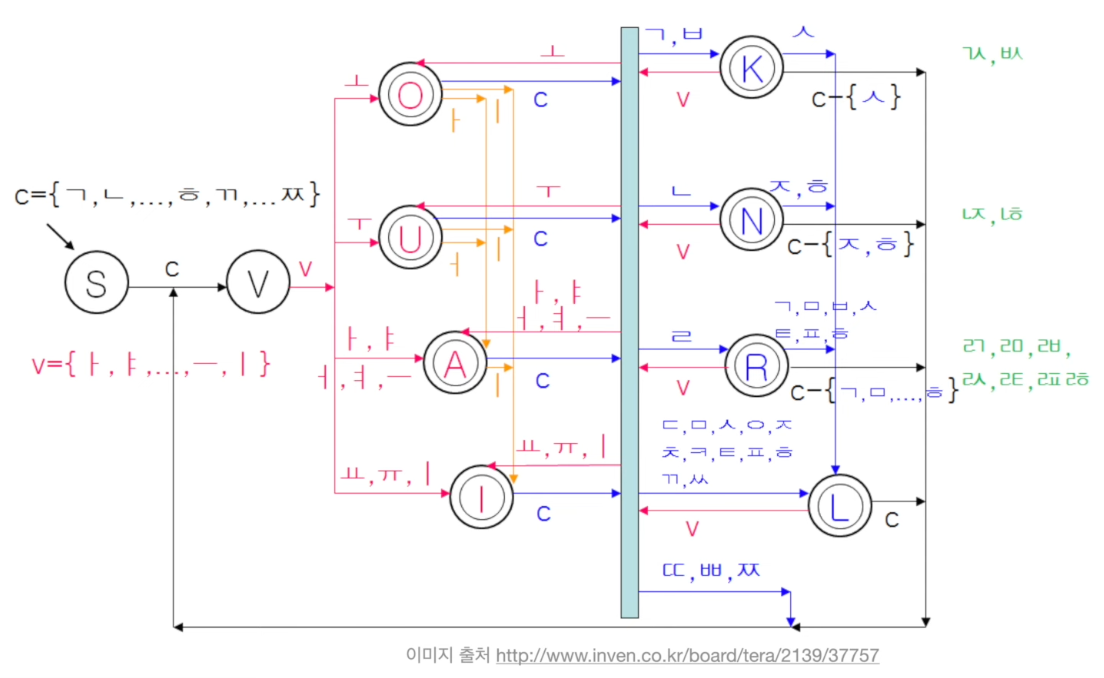
- 각 가능한 한글의 조합에 대해 오토마타를 표현한 그림
노엄 촘스키 형석언어 계층

- 제2,3 유형이 중요
- 제3유형은 DFA로 표현이 가능하고, 정규 문법을 가져야 함
- 세 가지 중 하나만 알아도 해당 언어를 표현할 수 있음
출처 https://trumanfromkorea.tistory.com/79 https://m.blog.naver.com/nextwebresearchlab/223155182748