로컬 환경과 가상환경
로컬과 리모트 컴퓨터
웹 서버에 배포를 해야하는 환경에서는 로컬에서 작업한 것을 리모트 컴퓨터에 복사해야 하는 상황이 생긴다.
 배포를 할 경우 우리가 항상 컴퓨터를 켜놓고 서버를 돌리지 않는 이상 24시간 돌아가는 서버를 구현하기에는 무리가 있기 때문이다.
배포를 할 경우 우리가 항상 컴퓨터를 켜놓고 서버를 돌리지 않는 이상 24시간 돌아가는 서버를 구현하기에는 무리가 있기 때문이다.
 이러한 배포를 도와주는 것이 리모트컴퓨터 말고 가상환경을 사용하는 경우도 있다.
이 가상환경은 물리적으로 존재하는 컴퓨터가 아닌, 다른 컴퓨터가 만들어내는 가상의 컴퓨터이다.
이러한 가상 환경은 3가지 종류를 가지고 있다.
이러한 배포를 도와주는 것이 리모트컴퓨터 말고 가상환경을 사용하는 경우도 있다.
이 가상환경은 물리적으로 존재하는 컴퓨터가 아닌, 다른 컴퓨터가 만들어내는 가상의 컴퓨터이다.
이러한 가상 환경은 3가지 종류를 가지고 있다.
- 에뮬레이션
- 모든 기능을 소프트웨어적으로 구현
- 가상화
- 주요 부품의 구현에서 하드웨어적 지원을 받음
- 반가상화
- 100% 완벽한 에뮬레이션과 가상화를 포기하고 가상머신 내 설치될 OS에 수정을 가하거나 전용 드라이버를 사용하여 하드웨어에 직접 접근
해당 가상환경은 구현 방식에 따라 성능과 범용성에서 차이가 난다.
퍼포먼스(속도) 에뮬레이션 < 가상화 < 반가상화
범용성의 경우 반가상화 < 가상화 < 에뮬레이션
환경의 차이
로컬 환경 (Local Environment)
로컬 환경은 개발자가 개발 및 테스트를 위해 자신의 개인 컴퓨터나 로컬 서버에서 사용하는 환경이다. 개인 컴퓨터 또는 로컬 서버를 사용하며
- 직접 접근 가능
- 테스트 및 디버깅 용이
- 개발 속도와 유연성이 높음 등의 장점이 있다.
가상 환경 (Virtual Environment)
가상 환경은 하드웨어 상에 가상으로 생성된 독립적인 실행 환경을 말하며 주로 여러 이유로 인해 별도의 격리된 환경을 필요로 할 때 사용된다. 이러한 경우는 위에서 말했던 배포 문제가 주가 된다. 가상 환경은
- 가상화 기술 사용으로 하나의 기기에서 여러개를 독립적 시행
- 환경 격리(독립성이 높아짐)와 관리가 용이함
- 서버 운영 및 확장성이 높음
- 테스트와 배포에 용이함 등의 장점을 가지고 있다.
웹 개발자의 경우 배포에 주로 사용하면서 Jenkins, Travis CI, Github Actions와 같은 배포를 용이하게 해주는 배포 파이프라인을 설정하는데 용이하며, 이를 통해 보다 쉬운 애플리케이션 유지보수가 가능해진다.
주요 차이점
두 환경의 차이점에는
- 접근성과 관리
- 로컬 → 개발자가 직접 접근하여 도구나 설정 관리
- 가상 → 시스템 리소스 보호관리
- 용도와 활용
- 로컬 → 개발 초기 단계에서 개발 및 테스트에 사용
- 가상 → 서버 운영 및 다양한 환경을 테스트 및 배포
- 유연성과 성능
- 로컬 → 개발속도와 유연성이 높음
- 가상 → 서버관리와 성능 최적화에 유리 가 있다.
이 가상환경에서 많이 쓰이는 OS인 Linux는 서버관리에 최적화된 OS로 알려져 있다. 그래서인지 이러한 Linux의 배포판인 우분투의 쉘스크립트를 이용해서 배포를 자동화시키는 방법 또한 다양하다. 우리가 원격 저장소(Github)에 올린 것들을 pull해와서 우분투의 환경 내에서 해당 프로젝트의 종속성을 설치하고, 빌드를 한 후에 환경변수 등을 세팅하여 배포를 보다 자동화시킬 수 있는 방법이 된다.
// 가상환경 내에서 프로젝트를 받아 저장
cd /home/ubuntu/github/client
git fetch
local=$(git rev-parse HEAD)
echo $local
target=$(git rev-parse origin/main)
echo $target
if [ $local != $target ]
then
git stash
git pull origin main
echo '풀 완료'
npm install
echo "npm install 완료"
npm run build
echo "빌드 완료"
fi리눅스(우분투)
파일 권한
를 사용하면 다음 이미지와 같이 출력된다.
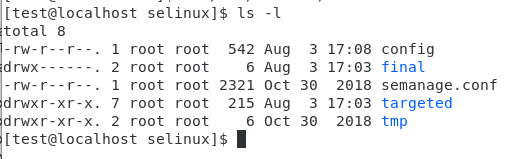
여기서 다음과 같이 일곱가지로 구분할 수 있다.
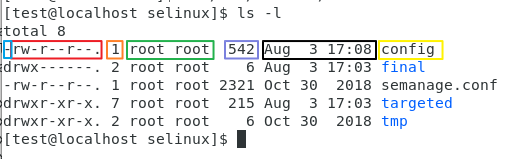
좌측 부터 파일 유형, 허가권, 링크 수, 소유자 / 소유그룹, 파일크기, 변경일시, 파일명으로 구분된다.
파일 유형 & 허가권
파일 유형
- : 일반 파일
d : 디렉토리
l : 심볼릭 링크
b : 블록 장치 파일
c : 문자 장치 파일
p : 파이프
s : 소켓
허가권
총 아홉개의 문자로 이루어져 있으며, 세 개씩 끊어서 해석하면된다.
r : 읽기 권한 (4) w : 쓰기 권한 (2) x : 실행 권한(1)
rwx에 대해 권한이 없을 경우 해당 자리를 -로 대체한다.
이미지에서 rw-r—r—으로 되어있다.
rw- / r— /r—로 구분할 수 있다.
첫 번째 그룹은 파일 소유자의 권한을 나타낸다.
두 번째 그룹은 파일 소유 그룹의 권한을 나타낸다.
세 번째 그룹은 다른 사용자의 권한을 나타낸다.
해당 권한에 대한 표현은 숫자로도 가능하다
chmod 777 test.sh위에 권한 옆 숫자가 각 권한이 나타내는 8진수이다. 해당 8진수를 통해서 세가지 권한 그룹에 대한 권한을 3개의 숫자만으로 표현을 할 수 있다. 예시로 chmod 764를 하게 된다면
- 7 (r+w+x, rwx)
- 6 (r+w, rw-)
- 4 (r,r—) 라고 해석하여 권한을 부여할 수 있다.
리눅스 명령어
알아둬야 할 리눅스 기본 명령어
| 명령어 | 설명 |
|---|---|
| pwd | 현재 디렉토리 확인 |
| ls(List Directory)(-[a]l) | 디렉토리의 내용 확인 |
| tree[디렉토리 이름][-L 깊이] | 디렉토리 깊이에 있는 파일 및 디렉토리 확인 |
| mkdir | 새로운 디렉토리 생성 |
| cd | 디렉토리 이동 |
| cat(concatenate) | 파일 내용 표시 |
| less 파일명 | 긴 파일의 내용을 끊어 표시 - 종료(q) - 처음으로(g) - 끝으로(G) -/단어 → 검색 |
| history | 명령어 이력 표시 |
| cp | 복사 |
| mv | 이동 |
| rm -rf | 삭제 |
| find 디렉토리 -name “파일이름” | 지정한 디렉토리와 하위 디렉토리에서 검색 |
| touch 파일이름 | 0바이트 파일 생성 |
| find 디렉토리 -name “파일이름” | 저장한 디렉토리와 하위 디렉토리에서 파일 검색 |
쉘 스크립트
쉘 스크립트는 쉘 명령어를 담은 스크립트로 일반적인 프로그래밍 언어와 비슷한 느낌이다. 하지만 우분투 내에서 텍스트에디터(nano, vi, vim)을 통해서 써야 한다는 점이 좀 킹받는다. 쉘 스크립트의 첫 줄을 쉬방(#!)으로 시작하며 스크립트가 어떤 인터프리터를 사용해서 실행될지를 나타낸다.
변수와 환경변수
- 변수
- 등호 앞뒤로 공백없이 작성
- 변수의 값을 참조하려면
$변수이름하거나${변수이름}으로 사용한다.
name="mh"
echo $name- 환경변수
- 환경변수는 사용자의 프로파일, 시스템설정, 쉘 세션 등 전반적인 환경에서 사용되는 변수이다.
- 대문자로 표기하는게 컨벤션이다.
- 주요 환경변수
- PATH: 실행 파일의 경로
- HOME: 사용자의 홈 디렉토리
- USER: 현재 사용자의 이름
- 환경변수 export 설정할 때는
export 변수명=값으로 설정할 수 있다.export만 치면 현재 설정되어 있는 환경변수를 볼 수 있다.
source 스크립트파일을 통해 스크립트를 실행한다- api key와 같은 보안에 중요한 값들은 무지성으로 원격저장소에 넣을 수 없기 때문에 셸에서 환경변수를 설정해주어 노출되지 않도록 해줄 수 있다.
- set
- 모든 셸 변수와 함수의 이름과 값을 설정/재설정하기 위한 입력이다.
- 읽기 전용 변수는 재설정 불가능
- https://www.gnu.org/software/bash/manual/bash.html#The-Set-Builtin
- env
- 현재 환경 변수를 표시하거나 환경 변수를 변경한 후에 프로그램을 실행하는 유틸리티이다.
env [OPTION]... [-] [NAME=VALUE]... [COMMAND [ARG]...]형태를 가진다.- -i option을 사용하면 환경변수를 모두 지운 후에 프로그램 실행이 가능하다.
실행
셸 스크립트의 실행 방식은 여러가지가 있다.
#!/bin/bash
echo "HELLO"
#권한을 바꿔야 실행이 된다.
$ chmod 권한 hello.sh
$ ./hello.sh
$리다이렉션 redirection
셸에서 입력과 출력의 방향을 바꾸는 명령어이다. 파일을 읽어서 표준 입력으로 전달하거나 표준 출력을 파일로 저장한다.
-
표준입력 0 : 키보드
-
표준입력 1 : 터미널
-
표준입력 2 : 터미널 화면
-
: 표준 출력을 지정 파일로(overwrite)
-
: 파일 쓰기(insert)
-
< : 파일 읽기
-
2> : 표준 에러를 지정 파일로
-
2>&1 : 표준 에러를 표준 출력으로
-
1>&2 : 표준 출력을 표준 에러로
# 파일 입력
$ command < infile
# 파일 출력
$ command > outfile
$ command >> outfile
$ command >& outfile
$ command >>& outfile
파이프 pipe
파이프는 command1 | command2와 같은 형태로 사용되고, command1의 표준 출력을 command2의 표준 입력으로 전달한다
&를 붙이면 표준 에러도 함께 전달한다
$ command1 | command2
$ command1 |& commnad2
# file.txt의 내용을 읽어서, grep의 입력으로 전달
$ cat file.txt | grep a메모리, CPU, RX/TX 보기
- CPU →
top-
- us : 프로세스의 유저 영역에서의 CPU 사용률
- sy : 프로세스의 커널 영역에서의 CPU 사용률
- ni : 프로세스의 우선순위(priority) 설정에 사용하는 CPU 사용률
- id : 사용하고 있지 않는 비율
- wa : IO가 완료될때까지 기다리고 있는 CPU 비율
- hi : 하드웨어 인터럽트에 사용되는 CPU 사용률
- si : 소프트웨어 인터럽트에 사용되는 CPU 사용률
- st : CPU를 VM에서 사용하여 대기하는 CPU 비율
-
- Memory →
free- SWAP메모리는 주 메모리
Mem이 거의 사용되었을 때 사용되는 메모리로, 주로 Mem을 보면 된다. - total : 총 메모리 양
- free : 사용가능한 메모리 양
- used : 사용중인 메모리 양
- buff/cache : IO와 관련되어 사용되는 버퍼에 사용되는 메모리
- buff : 커널 버퍼에서 사용되는 메모리
- cache : 디스크의 페이지 캐시
- SWAP메모리는 주 메모리
- RX/TX →
ifconfig대부분 해당 명령어를 통해 각 사용률을 본다.
키보드 입력
변수를 미리 만들어놓고 해당 변수에 내가 키보드로 입력한 값을 넣는다.
$ read INPUT
Hello
$ echo $INPUT반복 구문
- for loop
- for - do-done의 구조를 지닌다
- while [조건] loop
- while-do-done의 구조를 지닌다
연산 구문
#1. 더하기
expr 2 + 2
#2.빼기
expr 10 - 5
#3. 곱하기
expr 4 \* 3
#4. 나누기
expr 4 / 5
#5. 나머지
expr 6 % 5
# 변수 초기화
num1=10
num2=5
# 덧셈 연산
sum=$((num1 + num2))
echo "덧셈 결과: $sum"
# 뺄셈 연산
diff=$((num1 - num2))
echo "뺄셈 결과: $diff"
# 곱셈 연산
mul=$((num1 * num2))
echo "곱셈 결과: $mul"
# 나눗셈 연산
div=$((num1 / num2))
echo "나눗셈 결과: $div"
# 나머지 연산
mod=$((num1 % num2))
echo "나머지 결과: $mod"
-eq : 두 수가 같음(equal)
if [ "$a" -eq "$b" ]
-ne : 두 수가 같지 않음(not equal)
if [ "$a" -ne "$b" ]
-gt : 왼쪽이 오른쪽보다 더 큼(greater than)
if ["$a" -gt "$b" ]
-ge : 왼쪽이 오른쪽보다 더 크거나 같음(greater than or equal)
if [ "$a" -ge "$b" ]
-lt : 왼쪽이 오른쪽보다 더 작음(less than)
if [ "$a" -lt "$b" ]
-le : 왼쪽이 오른쪽보다 더 작거나 같음(less than or equal)
if [ "$a" -le "$b" ]
[ 부등호는 이중 소활호 (()) 에서 사용할 수 있다. ]
< : 왼쪽이 오른쪽보다 더 작음
if (( "$a" < "$b" ))
<= : 왼쪽이 오른쪽보다 더 작거나 같음
if (( "$a" <= "$b" ))
> : 왼쪽이 오른쪽보다 더 큼
if (( "$a" > "$b" ))
>= : 왼쪽이 오른쪽보다 더 크거나 같음
if (( "$a" >= "$b" ))
조건문
if-elif-else-fi의 구조를 지닌다.
만약 조건을 건다면 뒤에 then이 붙어야 하고, 조건식 바깥에는 대괄호와 세미콜론이 필요하다.
#!/bin/bash
if [ 조건식 ] # 조건식에는 아래 비교 연산자를 활용
then
명령어
elif [ 조건식 ]
then
명령어
else
명령어
fi
# 아래처럼 줄여서 사용도 가능하다.
if [ 조건식 ]; then
명령어
elif [ 조건식 ]; then
명령어
else
명령어
fi
# 이중 괄호로 조건식을 묶으면 산술 연산자(>,< 등)를 사용할 수 있다.
if (( 조건식 )); then
명령어
elif (( 조건식 )); then
명령어
else
명령어
fi
문자열 비교/패턴
- 문자열 비교
- 괄호 양 끝에 공간이 있다는 것을 중요하게 기억해야 한다.
[[ $a == $b ]]
[[ $a == hello* ]]
[[ $a != $b ]]파일, 디렉토리, 문자열 테스트 test
존재 여부를 판단하거나 파일 혁싱 등을 검사할 때 좋다.
# 파일이 있고 디렉터리인지
[ -d file ]
# 파일이 있고 일반 파일인지
[ -f file ]
# 파일이 있고 읽기 권한이 있는지
[ -r file ]
# 파일이 있고 실행 권한이 있는지
[ -x file ]
# 문자열이 있는지
[ -z string ]
awk
이건 뭔 약자인가 했는데 기능 디자인한 사람 이름이라고 한다(킹받네) awk는 파일로부터 레코드를 선택하고 선택된 레코드에 포함된 값을 조작하거나 데이터화하는 것을 목적으로 사용한다. awk는 명령을 통해 다양하게 할 수 있는 것들이 있다.
- 텍스트 파일의 전체 내용 출력
- 파일의 특정 필드만 출력
- 특정 필드에 문자열을 추가해서 출력
- 패턴이 포함된 레코드 출력
- 특정 필드에 연산 수행 결과 출력
- 필드 값 비교에 따라 레코드 출력

awk는 입력 데이터로부터 주어진 패턴을 포함하는 라인을 찾기 위해 파일의 내용을 탐색한 다음, 패턴에 일치하는 라인이 발견되면 해당 라인에 대해 지정된 액션을 실행하는 로직을 가지고 있다. 덕분에 인덱스를 넣어 값을 뽑아낼 수도 있고, 데이터화하기 좋게끔 필드를 출력할 수도 있다. 여기서 필드란 awk에서 분류하는 기준으로 공백 문자로 구분되는 것들이며, 라인 단위를 레코드(record) 라고 한다.
# 기본 구조
pattern { action }
# 세부 구조
awk [OPTION...] [awk program] [ARGUMENT...]
OPTION
-F : 필드 구분 문자 지정.
-f : awk program 파일 경로 지정.
-v : awk program에서 사용될 특정 variable값 지정.
awk program
-f 옵션이 사용되지 않은 경우, awk가 실행할 awk program 코드 지정.
ARGUMENT
입력 파일 지정 또는 variable 값 지정.활용법에 대해 아주 야무지게 설명을 해준 분이 계셔서 그대로 들고 왔다.
| awk 사용 예 | 명령어 옵션 |
|---|---|
| 파일의 전체 내용 출력 | awk '{ print }' [FILE] |
| 필드 값 출력 | awk '{ print $1 }' [FILE] |
| 필드 값에 임의 문자열을 같이 출력 | awk '{print "STR"$1, "STR"$2}' [FILE] |
| 지정된 문자열을 포함하는 레코드만 출력 | awk '/STR/' [FILE] |
| 특정 필드 값 비교를 통해 선택된 레코드만 출력 | awk '$1 == 10 { print $2 }' [FILE] |
| 특정 필드들의 합 구하기 | awk '{sum += $3} END { print sum }' [FILE] |
| 여러 필드들의 합 구하기 | awk '{ for (i=2; i<=NF; i++) total += $i }; END { print "TOTAL : "total }' [FILE] |
| 레코드 단위로 필드 합 및 평균 값 구하기 | awk '{ sum = 0 } {sum += ($3+$4+$5) } { print $0, sum, sum/3 }' [FILE] |
| 필드에 연산을 수행한 결과 출력하기 | awk '{print $1, $2, $3+2, $4, $5}' [FILE] |
| 레코드 또는 필드의 문자열 길이 검사 | awk ' length($0) > 20' [FILE] |
| 파일에 저장된 awk program 실행 | awk -f [AWK FILE] [FILE] |
| 필드 구분 문자 변경하기 | awk -F ':' '{ print $1 }' [FILE] |
| awk 실행 결과 레코드 정렬하기 | awk '{ print $0 }' [FILE] |
| 특정 레코드만 출력하기 | awk 'NR == 2 { print $0; exit }' [FILE] |
| 출력 필드 너비 지정하기 | awk '{ printf "%-3s %-8s %-4s %-4s %-4s\n", $1, $2, $3, $4, $5}' [FILE] |
| 필드 중 최대 값 출력 | awk '{max = 0; for (i=3; i<NF; i++) max = ($i > max) ? $i : max ; print max}' [FILE] |
자동화를 도와주는 crontab
crontab은 자동화를 도와주는 기능으로, 내가 설정한 시각마다 원하는 스크립트 파일이나 명령어를 실행시킬 수 있다.
# 크론탭 편집
$ crontab -e
# 크론탭 내용 보기
$ crontab -l
# 크론탭 지우기
$ crontab -r
# 크론탭 재시작하기
$ service cron restart또한 시각도 세부적으로 하나씩 설정해줄 수 있다. 심지어 요일까지 가능하다!
* * * * *
분(0-59) 시간(0-23) 일(1-31) 월(1-12) 요일(0-7)
# 매분 test.sh 실행
* * * * * /home/script/test.sh
# 특정 시간 실행
# 매주 금요일 오전 5시 45분에 test.sh 를 실행
45 5 * * 5 /home/script/test.sh
# 반복 실행
# 매일 매시간 0분, 20분, 40분에 test.sh 를 실행
0,20,40 * * * * /home/script/test.sh
# 범위 실행
# 매일 1시 0분부터 30분까지 매분 tesh.sh 를 실행
0-30 1 * * * /home/script/test.sh
# 간격 실행
# 매 10분마다 test.sh 를 실행
*/10 * * * * /home/script/test.sh
# 조금 복잡하게 실행
# 5일에서 6일까지 2시,3시,4시에 매 10분마다 test.sh 를 실행
*/10 2,3,4 5-6 * * /home/script/test.sh출처) https://recipes4dev.tistory.com/171 https://jdm.kr/blog/2